Politechnika Wrocławska, Wydział Elektroniki,
Kierunek: Informatyka, Semestr letni 2003/2004
INE 2022L -
laboratorium JĘZYKI PROGRAMOWANIA 1
( Propozycja programu laboratoriów do wykładu
prowadzonego przez dr Marka Piaseckiego
Konsultacje: wtorki i czwartki, godz. 13.15-15.00 pok. 324 C-3 )
-
Powtórzenie
- ćwiczenia z wykorzystaniem tablicowej reprezentacji danych.
-
Tablice
struktur - różne sposoby tablicowej implementacji listy
elementów.
-
Tablicowa
implementacja dynamicznej alokacji pamięci (przydziału elementu w
tablicy) oraz "dynamicznej" listy jednokierunkowej wiązanej za pomocą
indeksów.
-
Baza
danych osobowych porządkowana za pomocą kilku tablic indeksowych,
wykorzystująca dynamiczną alokację tablic na stercie.
-
Kolejka
FIFO (np. lista pacjentów do gabinetu lekarskiego)
zaimplementowana jako jednokierunkowa lista dynamiczna alokowana na stercie
-
Kolejka priorytetowa
(np. lista spraw do załatwienia,
z możliwością określania priorytetu - ważności spraw)
-
(oraz laboratorium nr
8) Projekt i implementacja systemu modelującego stan aktualny
oraz historię zmian koligacji rodzinnych dla zadanego zbioru osób.
-
Przebudowa programu z
laboratorium (7) i (8) do postaci projektu wielo-plikowego.
Przygotowanie biblioteki (pliki *.h oraz *.lib) implementującej
wybraną listę dynamiczną.
-
Ćwiczenia
z dowodzeniem prawdziwości formuł zapisanych za pomocą języka rachunku
zdań.
-
Dynamiczne i
statyczne testy oprogramowania
-
Pomiary złożoności
oprogramowania - złożoność strukturalna pojedynczego modułu/programu.
-
Pomiary złożoności
programów wieloplikowych - metryki międzymodułowe
SZCZEGÓŁOWE OPISY ZADAŃ LABORATORYJNYCH:
| LAB. 1) Powtórzenie - ćwiczenia z
wykorzystaniem tablicowej reprezentacji danych. |
Napisz program implementujący pojęcie
kolejki o ograniczonej pojemności
za pomocą standardowej tablicy
elementów o zadanej-stałej wielkości.
Należy uwzględnić wykonywanie
następujących operacji:
- sprawdzenie czy kolejka jest
pusta,
- wstawienie nowego elementu na koniec kolejki,
- pobranie elementu z początku kolejki,
- cofnięcie -
wstawienie elementu na początek kolejki.
Przykładowym tematem może
być np. oprogramowanie własnego "bufora klawiatury"
przechowującego
kody klawiszy zwykłych i "funkcyjnych" w postaci danych
dwu-bajtowych
(standardowa funkcja getch(), inaczej koduje klawisze zwykłe, a
inaczej "funkcyjne")
z możliwością cofania znaków - wstawiania dowolnej
ilości znaków na początek kolejki.
Należy rozważyć przynajmniej dwa
sposoby reprezentacji takiej kolejki:
a) Kolejność elementów w
tablicy odpowiada jeden-do-jeden kolejności elementów w
kolejce
(tzn. pierwszy element kolejki zawsze jest
elementem o indeksie 0 ).
Wówczas pobranie lub cofnięcie
kolejnego elementu do kolejki
wymaga przesunięcia
wszystkich pozostałych elementów.
b) tablica jest buforem cyklicznym a
dodatkowe zmienne (deskryptory) początek i koniec
wskazują
który element tablicy jest pierwszym elementem kolejki a który
ostatnim
W takim rozwiązaniu, pobranie lub cofnięcie kolejnego
elementu kolejki
wymaga jedynie cyklicznego powiększania lub
pomniejszania deskryptora "początek"
| LAB. 2) Tablice struktur - różne sposoby
tablicowej implementacji listy elementów. |
Celem ćwiczenia jest zaprojektowanie i
zaimplementowanie interfejsu
prostej bazy danych przechowującej
informacje o jednym zbiorze elementów
tego samego typu
(np. studentów w
grupie, towarów w sklepie, gości w hotelu, kont w banku, itp)
np.
struct BAZA {
//reprezentacja bazy w pamięci
komputera
#define ROZMIAR
100
ELEMENT tablica[ROZMIAR
];
//operacje wykonywane na
bazie
void
ZerujBaze(void);
int
IleElementow(void);
int DopiszElement( ELEMENT e
);
int
OdczytajElement( ELEMENT& e, int numer);
int UsunElement( int numer );
};
Podstawowym
elementem konstrukcyjnym bazy jest struktura ELEMENT,
której pola opisują
poszczególne parametry obiektu wybranej kategorii
(np. imię, nazwisko, data
urodzenia, ocena_z_laboratorium).
Cała BAZA jest przechowywana w
statycznej tablicy takich struktur (o stałej ilości
elementów).
Należy rozważyć przynajmniej dwa
sposoby reprezentacji takiej bazy danych:
a) Dane w przechowywane w
tablicy zajmują spójny obszar
od elementu BAZA[0] do
elementu BAZA[ilosc_wpisanych-1].
Oprócz tablicy
struktur ELEMENT konieczne jest jeszcze
wykorzystanie
dodatkowej zmiennej "ilosc_wpisanych"
przechowującej
informację o długości zajętego obszaru tablicy.
b) Dane nie muszą
zajmować spójnego obszaru w tablicy BAZA.
Strukturę
ELEMENT należy powiększyć o pole ZAJETE
informujące o
tym czy dana struktura zawiera zapisane dane
czy jest
obszarem wolnym/niewykorzystywanym.
Na początku
programu, pole ZAJETE w wszystkich strukturach tablicy
BAZA
powinno być wyzerowane.
Wówczas, implementacja operacji dopisania nowego elementu do
BAZY
powinna się rozpoczynać od wyszukania pierwszego
"wolnego" elementu
a usunięcie elementu z bazy
polegać będzie na wyzerowaniu pola ZAJETE
Ze względu na fakt, że
reprezentacja (a) była oprogramowana w poprzednim semestrze
WSKAZANE
jest zaimplementowanie reprezentacji (b) !
(*)
Bardziej zaawansowana tablicowa implementacja bazy (dla lepszych
studentów)
może wykorzystywać dynamiczną tablicę
struktur zamiast tablicy statycznej.
Wówczas stałą
ROZMIAR należałoby zastąpić zmienną "int rozmiar" o
wartości
inicjowanej w czasie alokowania pamięci na
tablicę zawierającą struktury ELEMENT
LAB. 3) Tablicowa
implementacja dynamicznej alokacji pamięci
(przydziału elementu w
tablicy)
oraz "dynamicznej" listy jednokierunkowej wiązanej za pomocą
indeksów. |
Celem ćwiczenia jest doskonalenie intuicyjnego
zrozumienia "wiązanych struktur danych" na przykładzie prostej listy
jednokierunkowej zbudowanej poprzez zapamiętywanie indeksów. Przykład
takiej reprezentacji, dla listy osób posortowanej według
nazwisk zilustrowano na rysunku poniżej:
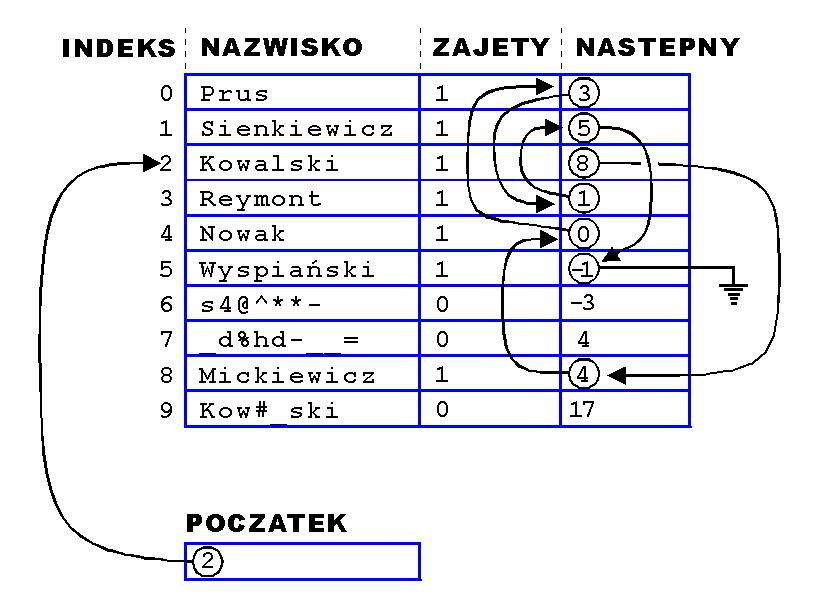
Uwaga 1: na kolejnych laboratoriach, takie modele
danych będą konstruowane za pomocą wskaźników oraz dynamicznej
alokacji pamięci na stercie. Tym razem należy je zrealizować za
pomocą statycznej tablicy struktur (analogicznej do zadania z laboratorium
2.b) oraz zapamiętywania indeksów kolejnych elementów w dodatkowym polu
"następny".
Przykładowa operacja
wyświetlenia zawartości takiej uporządkowanej listy struktur
ELEMENT :
struct
ELEMENT {
char
nazwisko[30];
int wiek;
float stypendium;
int ZAJETE;
int NASTEPNY;
};
zapisanej w strukturze BAZA (w postaci tablicą struktur ELEMENT
połączonych indeksami) może mieć następującą
postać:
#define _NULL_
-1
BAZA baza;
. . .
int
aktualny = POCZATEK;
while( aktualny != _NULL_
)
{
cout << endl
<< baza.tablica[aktualny].nazwisko << " ";
cout << baza.tablica[aktualny].wiek << " ";
cout << baza.tablica[aktualny].stypendium <<
endl;
aktualny = baza.tablica[ aktualny
].NASTEPNY;
}
W ramach laboratorium należy oprogramować
następujące operacje:
-
przydział nowego miejsca w tablicy (wyszukiwanie i
zaznaczenie wykorzystania),
taka operacja będzie odpowiednikiem
operatora "new",
-
zwolnienie miejsca w tablicy (odpowiednik operatora
"delete")
-
utworzenie pustej listy (np. POCZATEK = -1)
-
dodanie kolejnego elementu do listy uporzadkowanej
alfabetycznie w/g nazwisk
-
usunięcie wskazanego elementu z listy (wskazujemy poprzez
podanie indeksu/pozycji w tablicy),
-
wyświetlenie zawartości całej listy
-
wyświetlenie zawartości i-tego elementu listy.
PODPOWIEDZI
! |
W ramach wniosków należy
przygotować odpowiedzi na następujące pytania:
-
Czy usuniecie elementu z listy
jest równoważne zwolnieniu miejsca w tablicy ?
-
Czy usunięcie elementu z listy
powoduje wymazanie wszystkich danych
elementu w pamięci (np.
wymazanie nazwiska w tablicy struktur) ?
-
Czy nowo przydzielone
miejsca/obszary danych są wypełnione zerami ?
-
Co się stanie, jeżeli zwolnimy
obszar, który nie był wcześniej przydzielony ?
-
Co się stanie, jeżeli ponownie
przydzielimy obszar, który jest już wykorzystywany ?
LAB. 4) Baza danych osobowych porządkowana za pomocą
kilku tablic indeksowych,
wykorzystująca dynamiczną alokację tablic na stercie. |
Celem ćwiczenia jest rozbudowanie projektu
"bazy danych personalnych"
(wykonanego na laboratorium nr 2) o możliwości:
a) jednoczesnego uporządkowania według kilku różnych
kryteriów
(za pomocą "równoległych"
tablic indeksowych - patrz rys. poniżej)
b) dynamicznego ustalania rozmiaru wykorzystywanych
tablic danych i indeksów
poprzez wykorzystanie funkcji
malloc / realloc / free
lub operatorów new / delete.

Powiązanie tablic indeksowych z główną tablicą struktur może być
realizowane poprzez zapamiętywanie:
a) liczb całkowitych (int) -
indeksów elementów w tablicy
struktur STUDENT,
lub
b) wskaźników (STUDENT*)- adresów wskazujących
położenie kolejnych elementów w pamięci
Implementacja takiej bazy może wykorzystywać następujące struktury danych:
struct
STUDENT // struktura modelująca dane personalne studenta
{
char nazwisko[30];
int wiek;
float ocena;
char plec;
. .
.
};
struct INDEKS // modeluje tablicę indeksującą bazę według
jednego z kryteriów
{
int *tablica_indeksow;
// lub STUDENT* *tablica_wskaznikow;
int rozmiar_tablicy;
};
struct BAZA // struktura modelująca całą bazę
{
// reprezentacja bazy w pamięci
komputera
STUDENT *tablica;
int rozmiar_tablicy;
int ilosc_wpisanych_osob;
// reprezentacja aktywnego indeksu porządkującego elementy
INDEKS *aktywny_indeks;
. . .
};
LAB. 5) Kolejka FIFO (First In First Out)
np. lista pacjentów do gabinetu lekarskiego,
zaimplementowana jako jednokierunkowa lista dynamiczna alokowana na
stercie. |
Celem ćwiczenia jest zapoznanie się z pojęciem
rekurencyjnych struktur wiązanych.
W ramach laboratorium należy oprogramować jednokierunkową listę dynamiczną
z operacjami:
- DopiszNaKoniec
- PobierzKolejny
realizowanymi zgodnie ze standardem FIFO.
Elementy listy należy zdefiniować jako dynamicznie tworzone struktury ElementListy
które składają się z podstruktury typu DaneElementu zawierającej
dane pacjenta
oraz rekurencyjnego wskaźnika ElementListy* przechowującego adres
kolejnego elementu w dynamicznej pamięci komputera (na stercie):
np.
struct ElementListy
{
DaneElementu dane_pacjenta;
ElementListy* nastepny;
};
LAB. 7 i 8) Zaprojektowanie i oprogramowanie grafowej
reprezentacji relacji (koligacji)
rodzinnych zachodzących w dowolnym zbiorze osób. |
W ramach ćwiczenia trzeba przemyśleć i zaproponować
jak najlepsze rozwiązania
dla problemu reprezentacji grafu w pamięci operacyjnej i w pamięci
masowej (w plikach).
Przyjęte rozwiązanie należy przeanalizować pod kątem optymalizacji różnych
kryteriów:
np. czasu dostępu do elementów grafu, rozmiaru zajmowanego miejsca w pamięci/pliku,
modyfikowalności-łatwości dodawania lub usuwania nowych osób i relacji
pokrewieństwa.
W bardziej zaawansowanej wersji wybrana reprezentacja
powinna umożliwiać nie tylko modelowanie stanu aktualnego koligacji
ale również archiwizację informacji o rozmaitych zmianach zachodzących
z upływem czasu w zbiorze w/w relacji np. rozwody, ponowne małżeństwa,
adopcje.
Proszę pamiętać o możliwości powstania zapętleń typu
"zostanie swoim własnym wnuczkiem" (?!)
LAB. 10) Ćwiczenia z dowodzeniem prawdziwości formuł
zapisanych za pomocą
języka rachunku zdań. |
W ramach ćwiczenia należy wybrać dwie dowolne
tautologie z zestawu zamieszczonego
w materiałach do 9 wykładu (na stronie nr 5) i
wykazać ich prawdziwość metodami:
-
metodą zero-jedynkową
(poprzez "ręczne" sprawdzenie wszystkich
kombinacji wartości zmiennych zdaniowych
lub poprzez napisanie programu, który automatycznie sprawdzi
wszystkie kombinacje
- patrz str. nr 6 materiałów do wykładu)
-
metodą dedukcji naturalnej (można wykorzystać
dowodzenie wprost lub nie wprost)
W drugiej części ćwiczenia należy zmodyfikować
(popsuć) wybrane formuły tautologii
poprzez zamianę dowolnego funktora, zamianę zmiennych lub dopisanie nowych
elementów formuły
i ponownie sprawdzić, czy zmodyfikowana formuła nadal jest tautologią
(obydwoma metodami).
Rezultatem 10 laboratorium powinno być pisemne sprawozdanie
zawierające tabelki dokumentujące metodę zero-jedynkową,
(ewentualnie listing programu implementującego w/w metodę)
oraz pokazanie kolejnych kroków dowodu metodą dedukcji naturalnej.
| LAB. 11) Dynamiczne i statyczne testy oprogramowania |
W pierwszej części tego laboratorium należy
przeprowadzić testy dynamiczne oprogramowania
i ocenić ich skuteczność w wykrywaniu błędów weryfikowanego programu.
W tym celu studenci powinni rozmyślnie wprowadzić jakiś błąd
(np. usunięcie linii programu, zamiana kolejności instrukcji, zmiana warunku
pętli itp)
do jednego ze swych dotychczasowych programów
(np. do programu drzewa genealogicznego)
a następnie przekazać koledze/koleżance tylko wersję wykonywalną (EXE)
z poleceniem wykrycia wprowadzonego błędu.
Rezultatem tej części powinien być pisemny opis przeprowadzanych testów
oraz wnioski odnośnie prawdopodobnych przyczyn wykrytych objawów błędnego
działania.
W drugiej części ćwiczenia, studenci wymieniają się kodem źródłowym
programów,
(które były testowane dynamicznie w pierwszej części laboratorium)
i przeprowadzają testy statyczne dla tej części programu (np. jednej
operacji/funkcji)
którą na etapie testowania dynamicznego wskazano jako najbardziej
prawdopodobną przyczynę błędów.
Testy statyczne należy zdokumentować tabelką lub grafem ilustrującym
przebieg analizy kolejnych punktów rozgałęzień w programie
(patrz strony 3-8 w materiałach do 10 wykładu)
LAB. 12) Pomiary złożoności oprogramowania
- część 1- pomiary złożoności strukturalnej pojedynczego modułu
(programu) |
W ramach ćwiczenia należy dokonać pomiaru złożoności
pierwszego programu laboratoryjnego
(funkcje i dane implementujące kolejkę o ograniczonej pojemności)
Należy policzyć metryki modułowe (opisane w materiałach
do 11 wykładu):
-
metryki rozmiaru: SLOC, S/C,
-
metryki przepływu sterowania - liczby cyklomatyczne
McCabe: VLI(G) lub V(G)
-
metrykę spójności: LCOM
Uzyskane wyniki należy następnie porównać z
wynikami uzyskanymi przez pozostałych
studentów w grupie.